Ora si andranno a verificare i risultati che si riescono ad ottenere con le reti neurali (NN) per confrontare le due applicazioni illustrate precedentemente (KR e FKR) con una metodologia ben affermata nel mondo finanziario (NN) e trarre alcune conclusioni. In questa sezione si andrà ad illustrare i risultati che si sono ottenuti applicando una semplice rete neurale artificiale (NN) a propagazione unidirezionale (feed-forward) con supervisore (y) per trattare la stessa matrice dati del cap. 4.1.
L’architettura della rete è la seguente:
− uno strato di input con: − 10 nodi: 10 candidate predictors (tabella A); − 3 nodi: 3 best predictors (tabella B); − uno strato nascosto (layer one) con: − n nodi, dove n va da 5 a 15 (tabella A); − n nodi, dove n va da 1 a 11 (tabella B); − uno stato di output con un unico nodo; − funzione d’attivazione tra input e layer one sigmoide ( ‘tagsin’); − funzione d’attivazione tra layer one e output lineare (‘purelin’); − back propagation network training function (‘trainlm’); − back propagation weight/bias learning function (‘learngdm’); − performance function ('mse'); in linguaggio Matlab: net=newff(minmax(DATA(:,[X y]),[n,1], . . . {'tansig','purelin'},'trainlm','learngdm','mse');
I parametri di training sono i seguenti:
net.trainParam.epochs=100; % Maximum number of epochs to train net.trainParam.goal=0; % Performance goal net.trainParam.max_fail=5; % Maximum validation failures net.trainParam.mem_reduc=1; % To use for memory/speed tradeoff net.trainParam.min_grad=1e-10; % Minimum performance gradient net.trainParam.mu=0.001; % Initial Mu net.trainParam.mu_dec=0.1; % Mu decrease factor net.trainParam.mu_inc=10; % Mu increase factor net.trainParam.mu_max=1e10; % Maximum Mu net.trainParam.show=10; % Epochs between showing progress net.trainParam.time=inf; % Maximum time to train in seconds Dopo aver addestrato la rete e misurato il tempo di addestramento: tic; net=train(net,X.lrn,y.lrn); toc;
con la simulazione della stessa:
ycalc.tst=sim(net,X.tst); ycalc.evl=sim(net,X.evl); si sono calcolate alcune misure di performance, tra le quali VR. I risultati sono riportati di seguito nelle tabelle A e B.
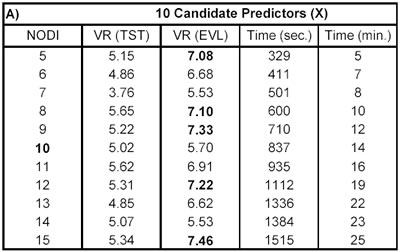
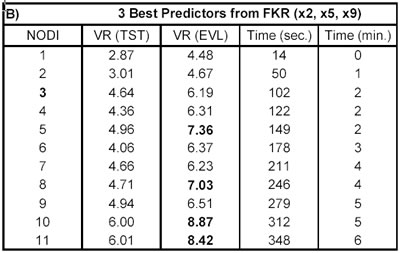
Come si può notare non ci sono grosse differenze tra le performance della rete neurale applicata a tutti i candidate predictors (tab. A) e quella applicata solo ai tre best predictors (tab. B), dove i tre predictors sono definiti best per costruzione (vedi M-script cap. 4.1), ma anche dalla kernel regression. Tuttavia, si possono osservare delle importanti riduzioni nel tempo computazionale (Time), quando si riducono i nodi di input della rete.
Successivo: 4.5 Considerazioni Finali
Sommario: Index