Il modellamento di serie storiche finanziarie richiede lo sviluppo di modelli che riescano a trattare migliaia di records e centinaia di candidate predictors in tempi quanto più brevi tanto più è elevata la frequenza di campionamento dei dati con la quale si opera. È importante, perciò, tener sotto controllo la complessità computazionale del metodo di modellamento adottato. Con un computer che ha un singolo processore, il tempo totale richiesto per il modellamento è stimato come segue:
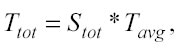
Stot è il numero totale di spazi esaminati e Tavg è il tempo medio necessario per studiare ciascun spazio. Mentre precedentemente sono stati trattati alcuni aspetti relativi al controllo degli spazi totali da analizzare (cap. 2.5), ora l’enfasi cade anche sul tempo medio necessario per analizzare ogni spazio: questi sono entrambi aspetti fondamentali per l’efficienza di un metodo di modellamento.
Applicando un approccio semplice di kernel regression, i calcoli richiesti per valutare un singolo spazio sono nell’ordine di O(nlrn*ntst) e il tempo medio necessario tende ad essere proporzionale a tale cifra (cap. 2.3), così che, quando si lavora con decine di migliaia di records, il valore di Tavg diventa intollerabilmente grande. Il concetto delle bande descritto nel cap. 2.3 dovrebbe offrire un sensibile miglioramento nella velocità dell’applicazione: la riduzione dei punti di learning usati per stimare ogni test point, infatti, comporta un numero minore di calcoli da effettuare.
Tuttavia anche con l’utilizzo della bandwidth vengono computate tutte le distanze tra i punti di learning e ciascun punto di test. Solo successivamente vengono rigettati tutti i punti di learning troppo distanti e considerati solo quelli con distanza minore di h (l’ampiezza della bandwidth), che verranno pesati con il kernel per stimare i valori di y in ogni test point.
Un altro inconveniente nell’utilizzo della bandwidth è che non sempre la densità dei dati è costante in tutti gli spazi: in uno spazio alcune regioni possono avere una grande concentrazione di learning points, mentre altre possono essere scarsamente popolate.
Se si considera un’unica banda di ampiezza h per tutti gli spazi, può succedere che alcuni punti di test vengono stimati attraverso molti learning points, mentre altri punti di test da pochi se non da pochissimi, o addirittura non possono essere stimati per mancanza di punti di learning, con la conseguenza di avere stime puntuali con varianze diverse.
Si devono quindi sviluppare metodi che riescano rapidamente a localizzare i punti più vicini, senza incorrere nei problemi elencati; questo è un tipico problema di geometria computazionale.
Successivo: 3.2 Il P-TREE
Sommario: Index