Il modello più semplice di kernel regression è chiamato algoritmo di ordine 0 oppure Nadaraya-Watson estimator:

j è il valore di y stimato per il j-esimo punto del test set, i y è il valore osservato di y nell’i-esimo punto di learning; potrebbe essere calcolato anche per tutti i valori di LRN e non solo per quelli di testing, ma questo richiederebbe più tempo d’analisi. Questo algoritmo è detto di ordine 0 perché si serve di una costante (polinomio di ordine 0) per il calcolo di : j è calcolato, infatti, come una media pesata dei valori di y del learning set (yi). Dato un record j la previsione si ottiene usando i records di learning che sono più simili a j. La similarità è misurata come la media delle distanze al quadrato definite nell'iperspazio
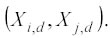
I regressori kernel ottengono la previsione di yj con la media pesata di yi dei suoi nearest neighbors. I pesi
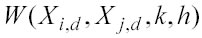
di ogni neighbor vengono determinati con il kernel (cap. 2.2 e cap. 2.3). Un algoritmo più evoluto di kernel regression si chiama algoritmo di ordine 1, il quale applica, al posto di una semplice media ponderata, un polinomio di primo ordine. Ad una dimensione tale polinomio è una retta:
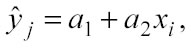
In p dimensioni si ha invece un iperpiano:
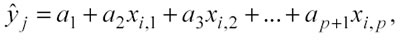
dall’espressione si deduce che per la previsione nel caso di un algoritmo di ordine 1 sono necessari p+1 coefficienti. Si possono definire algoritmi di ordine superiore come l’algoritmo di ordine 2, basato su un polinomio di secondo ordine, se si considera una sola dimensione si ottiene una parabola:
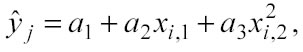
generalizzando, per p dimensioni si ha invece:

come si può osservare, più la dimensionalità dello spazio cresce, più il numero di coefficienti necessari per espletare il modello aumenta rapidamente. In generale il numero di coefficienti richiesti per “fittare” spazi pdimensionali con algoritmi di ordine 2 è pari a:
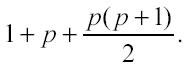
In applicazioni con una grande componente d’errore nel segnale, come il modellamento dei mercati finanziari, utilizzare algoritmi di ordine superiore a 2 non migliora il risultato finale. In ogni caso, l’aumento dell’ordine accrescerebbe la complessità di calcolo e condurrebbe alla perdita di efficienza della metodologia di modellamento, poiché a differenze minime in efficacia corrisponderebbero grandi scostamenti nella complessità computazionale. Si ritiene perciò che sia più che sufficiente considerare solamente gli algoritmi di ordine 0, 1, 2.
Una volta scelto l’ordine, i coefficienti vengono determinati per ogni punto del test set utilizzando i punti di learning. A questo scopo vengono usate tecniche di programmazione lineare, tipicamente il metodo dei minimi quadrati ponderati.
Successivo: 2.5 la dimensionalità del Polinomio
Sommario: Index