Il concetto di banda (bandwidth) completa la funzione kernel (eq. 2.2.2) ridefinendo l’equazione 2.2.1 come segue:
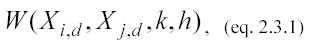
dove il nuovo parametro h stabilisce l’ampiezza dell’intervallo di banda. La bandwidth è definita come la regione in cui il peso (W) esercita la sua influenza, in altre parole, per un punto xj del test set solo i punti xi del learning set più vicini a xj ed interni all’intervallo [xj–h/2; xj+h/2] sono utilizzati e pesati per stimare y. Paradossalmente, se non ci sono punti di learning che cadono in questa regione, y non può essere stimato. Come soluzione a questo problema spesso si ricorre all’approccio K-nearest neighbor estimate, metodo che va a pesare solo i primi K punti più vicini al punto considerato.
Comunque in presenza di un’alta densità di dati, l’uso di una bandwidth costante resta ancora una scelta ragionevole. Per estendere il concetto della banda in p dimensioni è necessario ridefinire la distanza al quadrato della funzione kernel (eq. 2.2.2) e basare la bandwidth su questa distanza.
È chiaro che, se le variabili indipendenti (Xd) avessero scale molto differenti, la dimensione più lunga dominerebbe totalmente il calcolo. Per risolvere questo problema bisogna utilizzare una sorta di distanza normalizzata. Il metodo più comune per normalizzare una distanza è quello di dividere i valori di tutte le dimensioni per il relativo range (range = xmaxd – xmind) oppure per la deviazione standard corrispondente ad ogni dimensione.
In uno spazio a più dimensioni il valore della distanza normalizzata tra il j-esimo punto del test set e l’i-esimo punto di learning è calcolata come segue:
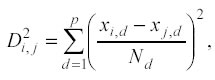
dove xi,d è la variabile della d-esima dimensione nell’i-esimo punto di learning, e allo stesso modo, xj,d è la variabile della d-esima dimensione per il j-esimo punto di testing; Nd è invece la costante di normalizzazione (range o deviazione standard) per la d-esima dimensione.
Solitamente è più vantaggioso lavorare con 2,
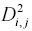
piuttosto che con
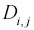 perché si elimina la necessità di calcolare le radici quadrate, risparmiando
tempo computazionale.
La ragione primaria dell’introduzione del concetto di banda è quella di
eliminare l’effetto dei punti molto distanti nella stima di un dato punto di testing.
A tal fine si potrebbe pensare che una costante di smussamento (k)
molto elevata (~1) possa risolvere il problema, ma così facendo si rischierebbe
di ridurre troppo lo smussamento fino ad arrivare al caso limite di ottenere
una stima basata primariamente solo sul singolo punto più vicino ad
ogni punto di test.
perché si elimina la necessità di calcolare le radici quadrate, risparmiando
tempo computazionale.
La ragione primaria dell’introduzione del concetto di banda è quella di
eliminare l’effetto dei punti molto distanti nella stima di un dato punto di testing.
A tal fine si potrebbe pensare che una costante di smussamento (k)
molto elevata (~1) possa risolvere il problema, ma così facendo si rischierebbe
di ridurre troppo lo smussamento fino ad arrivare al caso limite di ottenere
una stima basata primariamente solo sul singolo punto più vicino ad
ogni punto di test.
Il secondo motivo per il quale converrebbe l’uso della banda h oppure del K-nearest neighbor estimate, è dato dal risparmio in tempo di calcolo: la complessità computazionale rimane O(nlrn*ntst) per quanto concerne il calcolo delle distanze, ma ricorrendo alla banda si riducono ad h i punti di learning pesati per stimare ogni valore di test.
Se si pensa che, di norma, si possono avere valori di nlrn e ntst nell’ordine di alcune migliaia e che già nell’inizializzazione di una matrice di tali dimensioni certe applicazioni e/o computer si bloccano, tale riduzione dei calcoli (h è nell’ordine delle centinaia) non è un risultato da poco. Tuttavia, per diminuire ulteriormente la complessità computazionale, che rimane pur sempre elevata, si utilizzano sistemi di regressione kernel ad alta performance con l’inserimento del p-Tree (cap. 3).
Successivo: 2.4 L'ordine del Polinomio
Sommario: Index