Prima di procedere a verificare che i residui si distribuiscano secondo una variabile aleatoria normale, andiamo ad esaminare i residui al fine di individuare dei valori anomali. È preferibile operare sui residui standardizzati per avere a che fare con numeri puri. A tal scopo andiamo a scrivere una semplice funzione che standardizza il vettore dei dati in input:

Creiamo il vettore dei residui standardizzati e ne tracciamo il grafico (Graf. 15):

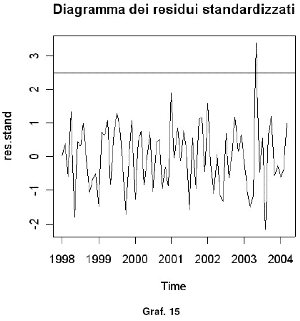
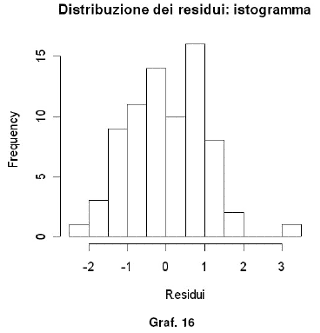
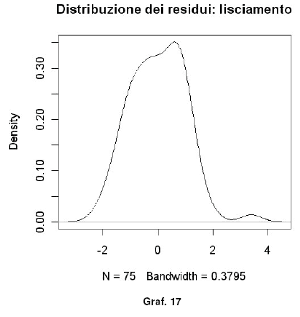
Dal diagramma emerge che una sola osservazione (maggio 2003) risulta essere anomala poiché si trova al di là della banda di confidenza del 99% (banda compresa tra –2,5 e +2,5). È necessario analizzare questo outlier e comprendere quali motivazioni lo hanno determinato, ed esempio potrebbe essere stato causato da un fatto episodico o comunque circoscritto ed individuabile, ed in caso estremo potrebbe essere necessario eliminarlo. Dal grafico può supporsi che agli errori sottenda un processo stocastico di tipo white noise. Un modo abbastanza semplice ed intuitivo per verificare la normalità della distribuzione degli errori è quello di ricorre all’ausilio grafico con un istogramma (Graf. 16 e 17) e con un QQ-plot (Graf. 18).
hist(res.stand,main="Distribuzione dei residui: istogramma",xlab="Residui")
plot(density(res.stand,kernel="gaussian"),main="Distribuzione dei residui: lisciamento")
qqnorm(res.stand) abline(0,1)
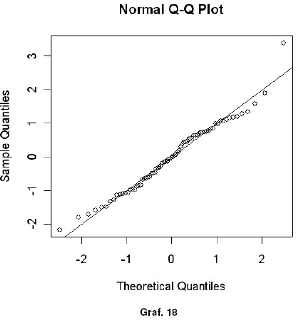
Tutti e tre i grafici ci danno una buona indicazione per una probabile distribuzione pressoché normale dei residui. Per avere un risultato statisticamente più affidabile bisogna effettuare dei test di normalità. Ne effettueremo due: quello di Wilk – Shapiro e quello di Jarque – Bera. Per completezza informiamo che il package nortest fornisce ulteriori test statistici per verificare la normalità.
Vito Ricci
Successivo: Test di Wilk - Shapiro
Sommario: Index