Accueil >
Analyse technique >
Predictibilite et Profitabilite des figures Chartistes >
La modélisation
L’utilisation ou non des prix les plus hauts (High) et les plus bas (Low) impliquent l’utilisation de deux méthodes différentes de détection des extremums locaux. La première sous-section présente la méthode de détection quand uniquement le cours dit de clôture est utilisé. La seconde présente celle quand les cours High et Low sont exploités.
Détection des extremums sur la base du cours dit de clôture
Nous disposons au préalable d’une série de prix correspondant au dernier cours pour chaque intervalle de temps {Pt : t = 1,...,T }. De cette série, nous ne prenons qu’une fenêtre de taille l [22]:
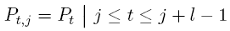 (18)
(18)
avec j = 1,...,T - l +1. Ensuite, pour chaque fenêtre j, nous supposons la relation suivante:
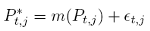 (19)
(19)
où εt,j est un bruit blanc et m(Pt,j) est une fonction non linéaire estimée par la méthode de noyau.
Pour un x quelconque, un estimateur de lissage de m(x) s’exprime par:
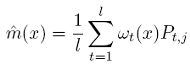 (20)
(20)
où la pondération ωt(x) est importante pour les Pt,j proche de x et faible pour ceux loin de x. Pour un estimateur de noyau (kernel), la fonction de pondération ωt(x) est construite à partir d’une fonction de densité de probabilité, également appelée kernel :
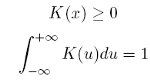 (21) (22)
(21) (22)
Il est possible de changer l’étendue de ce kernel en mettant cette fonction à l’échelle requise via l’utilisation d’un paramètre h > 0 :
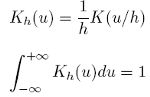 (23) (24)
(23) (24)
et de définir la fonction de pondération utilisée dans la moyenne pondérée :
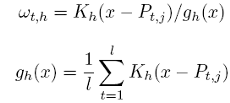 (25) (26)
(25) (26)
De la sorte, nous obtenons un estimateur kernel de Nadaraya-Watson ˆmh(x):
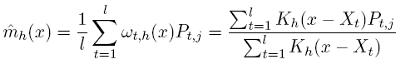 (27)
(27)
Si h est petit, la moyenne sera effectuée en ne prenant en considération qu’un petit entourage autour de chaque Pt,j et inversement. Ainsi, le paramètre h, appel é largeur de bande ou paramètre de lissage, permet de contrôler le niveau du lissage. Le choix d’une largeur de bande adéquate est un aspect important pour toute technique de lissage . Tout comme Lo, Mamaysky, and Wang (2000) , notre choix s’est porté vers la plus populaire des fonctions kernel utilisées, à savoir la Gaussienne [23] :
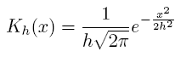 (28)
(28)
Comme pour n’importe quelle méthode de lissage, la sélection d’une largeur de bande appropriée est le point clé du succès de ˆmh() dans l’approximation de m() : faire la moyenne de trop peu d’éléments conduit à une estimation trop erratique et le contraire à une fonction trop lisse. Silverman (1986) propose comme valeur pour le paramètre de lissage, hopt,j :
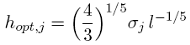 (29)
(29)
où σj représente l’écart-type de la distribution des observations comprises dans la fenêtre j. Toutefois, la largeur de bande optimale obtenue par l’équation (29) est trop large, les données étant trop lissées. De manière à avoir graphiquement le lissage désiré, nous avons donc choisi une valeur pour le paramètre de lissage correspondant à 20% de la valeur obtenue par l’équation (29):
h* = 0.2 x hopt,j (30)
L’estimation de m() s’effectue donc à l’aide d’un estimateur kernel de Nadaraya- Watson ˆmh(Pt,j ). Après cela, nous déterminons l’ensemble des maximums maxˆmh(Pt,j ) et des minimums minˆmh(Pt,j ) de la série ˆmh(Pt,j ):
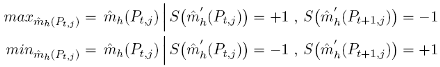 (31) (32)
(31) (32)
où S(X) est une fonction qui vaut +1 (-1) quand le signe de X est positif (négatif) et ˆm' h(Pt,j) est la dérivée de ˆmh(Pt,j ). Précisons que nous avons bien une alternance de maximum et de minimum de part sa construction. De ces deux ensembles, nous tirons ensuite les moments tM( ˆmh(Pt,j)) et tm( ˆmh(Pt,j)) correspondant respectivement aux moments d’observations des maximums et des minimums:
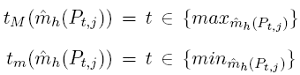 (33) (34)
(33) (34)
L’étape suivante est par conséquent de trouver les extremums correspondant sur la série de cours dit de clôture :
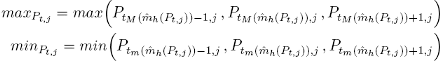 (35)(36)
(35)(36)
Suite à cela, nous disposons ainsi des maximums maxPt,j et minimums minPt,j locaux pour chaque fenêtre j. Ces deux séries d’extremums sont disposées de manière à avoir une seule série d’extremums {Ei,j : i = 1,...,I} avec I correspondant au nombre d’extremums observé dans la fenêtre j. L’alternance entre maximum et minimum, sur la série originelle, est respectée étant donnée la valeur de h qui assure que deux extremums sur ˆmh(Pt,j) sont séparés d’au moins 2 intervalles de temps. Par conséquent, les séquences d’extremums Ei,j sont ensuite analysées en vue d’observer si ces dernières correspondent à l’une des définitions quantitatives des figures chartistes présentées dans la section 3.2. Si la même séquence d’extremums est observée dans plusieurs fenêtres, seule sa première observation est analysée, afin d’éviter la duplication des résultats.
22. Dans ce travail, nous avons fixé l à 36.
23. Nous avons également eu recours à une fonction kernel quadratique mais les estimations n’étaient pas adéquates. Notre choix s’est aussi porté sur d’autres techniques de lissage telles que les splines cubiques et les approximations polynomiales, mais sans résultats convaincants.
Prof. Walid Ben Omrane et Hervé Van Oppens
Suivant: Détection des extremums sur la base des cours High et Low
Sommaire: Index