Home >
Doc >
Reti neurali artificiali per la valutazione di opzioni >
La fase di pre-processamento dei dati - 4.3
Consideriamo ora le operazioni necessarie alla costruzione del set di dati da utilizzare. Come evidenziato, la fase di processamento dei dati prevede:
. la selezione di un opportuno sottoinsieme dei dati disponibili (operazione di filtraggio dei dati);
. l'opportuna ridefinizione dei pattern di input e di quelli di output (operazione di trasformazione dei dati). La prima operazione è necessaria al fine di escludere, secondo opportuni criteri, esempi ritenuti non significativi e, quindi, aventi scarso contenuto informativo. I criteri utilizzati sono stati i seguenti (per maggiori dettagli si veda [Anders et al., 1998]):
. vengono escluse le opzioni eccessivamente deep-in-the-money oppure deep-out-ofthe-money perché, generalmente, risultano scarsamente trattate;
. vengono escluse le opzioni con scadenza inferiore ad un prefissato numero di giorni; infatti, tali opzioni risultano trattate nel mercato al loro valore intrinseco e possono implicare errori rispetto ai prezzi teorici;
. vengono escluse le opzioni trattate a prezzi troppo bassi; infatti, si può empiricamente notare come, soprattutto per i prezzi delle opzioni più vicini allo zero, vi sia un numero elevato di opzioni trattate allo stesso valore. Quindi, in questi casi la RNA può avere, delle difficoltà nell'associare a pattern di input anche molto diversi fra di loro lo stesso output [Tale criterio ha come ulteriore vantaggio anche quello di ridurre in modo drastico il totale esempi].
Le variabili che influenzano il prezzo di un'opzione, avente come attività sottostante un indice azionario, secondo il modello B-S sono sei. In particolare, dalla relazione (4.2.1) si ha che il valore di un'opzione call di tipo europeo ( 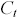 ) è funzione del valore dell'indice (
) è funzione del valore dell'indice ( 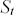 ), del prezzo di esercizio (
), del prezzo di esercizio ( 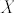 ), del tempo mancante a scadenza (
), del tempo mancante a scadenza ( 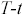 ), della volatilità (
), della volatilità ( 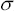 ), del tasso d'interesse privo di rischio (r) e del tasso di dividendo (d). In particolare, la formula B-S può essere riscritta considerando le seguenti
), del tasso d'interesse privo di rischio (r) e del tasso di dividendo (d). In particolare, la formula B-S può essere riscritta considerando le seguenti
semplificazioni:
. si utilizza come tasso d'interesse privo di rischio la differenza tra l'originario tasso
d'interesse privo di rischio ed il tasso di dividendo, cioè r-d;
. si utilizza il rapporto tra il valore dell'indice ed il prezz d'esercizio 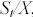 , ciò al fine di determinare il rapporto tra il prezzo dell'opzione ed il prezzo d'esercizio
, ciò al fine di determinare il rapporto tra il prezzo dell'opzione ed il prezzo d'esercizio 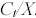 .
.
Pertanto, gli input effettivamente necessari sono quattro. In particolare, l'ultima semplificazione considerata si ottiene ipotizzando che la distribuzione del rendimento dell'attività sottostante l'opzione sia indipendente dal livello del prezzo dell'attività stessa. Secondo il Teorema 9 enunciato da Merton in [Merton, 1973] questo implica che la funzione 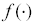 sia omogenea di grado 1 rispetto al valore del sottostante ed al prezzo d'esercizio. Poiché la formula B-S rientra in tale categoria, utilizzando tali input per la RNA molti Autori ipotizzano che anche la formula di valutazione dell'opzione lo sia. Le motivazioni alla base di tale semplificazione sono le seguenti:
sia omogenea di grado 1 rispetto al valore del sottostante ed al prezzo d'esercizio. Poiché la formula B-S rientra in tale categoria, utilizzando tali input per la RNA molti Autori ipotizzano che anche la formula di valutazione dell'opzione lo sia. Le motivazioni alla base di tale semplificazione sono le seguenti:
. viene utilizzata una RNA con nodo di input in meno, riducendo il numero dei parametri e quindi la complessità del problema,
. si ritiene che questo permetta alla RNA di apprendere più facilmente la struttura della volatilità implicita di mercato (il così detto effetto smile si rappresenta graficamente mettendo in relazione la volatilità implicita e, appunto, il rapporto
St/X).
Quindi, la funzione (incognita) che andiamo ad approssimare è:
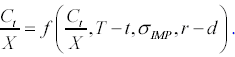
Ciascun esempio sottoposto alla rete sarà, quindi, composto da cinque valori, di cui quattro relativi all'input ed 1 relativo all'output desiderato.
Successivo: La fase di apprendimento
Sommario: Indice