Home >
Doc >
Reti neurali artificiali per la valutazione di opzioni >
La costruzione del modello neurocomputazionale
Secondo quanto richiesto all'approccio quantitativo di cui in analisi e date le caratteristiche dei metodi e degli strumenti neurocomputazionali considerati (così come presentati nella sezione 2), in questa terza sezione si propone la puntuale specificazione di un articolato modello il cui "motore" è costituito da una RNA ad apprendimento supervisionato di tipo MLP. Più in dettaglio, il seguito di questa sezione si propone la specificazione vera e propria del modello neuronale.
In generale, nell'ambito dell'implementazione e dello sviluppo di una efficace RNA di tipo MLP ad apprendimento supervisionato, vi sono vari aspetti ai quali si deve obbligatoriamente prestare attenzione, aspetti quali:
. quelli provenienti dalla teoria della neurocomputazione come, ad esempio, la metodologia di discesa rapida del gradiente (ad esempio si riveda l'algoritmo EBP alla sottosezione 2.2),
. e quelli emergenti durante la fase di implementazione operativa, come, ad esempio, il problema della selezione di un'opportuna classe di modelli neuronali capaci di affrontare lo specifico problema considerato. Con riferimento all'analisi qui in via di sviluppo, l'insieme di tali aspetti può essere raggruppato nelle tre seguenti principali classi operative:
. una prima classe in cui si prende in considerazione la selezione delle variabili di input e di quelle di output e si prendono in considerazione le eventuali operazioni di pre- e post-processamento dei dati;
. una seconda classe operativa in cui esamina l'aspetto del design architetturale del modello;
. ed una terza ed ultima classe in cui si prevede l'analisi della procedura di training e di quella di testing.
Tabella 3.1 - Classi operative
| Classe 1 Selezione degli input e degli output Pre- e post-processamento dei dati |
- Selezione delle variabili di input ed output - Processamento dei dati . Filtraggio dei dati . Trasformazione dei dati |
| Classe 2 Design del modello MLP - Strutture architetturali |
. Struttura della regione nascosta . Numero dei nodi presenti nello strato di input e di output e negli strati nascosti . Morfologia delle connessioni |
| Classe 3 Procedure di training e di testing - Selezione delle funzioni di trasferimento - Procedure di training |
. Algoritmo di training . Gestione del tasso di apprendimento e del momentum - Regole di Stop Learning - Inizializzazione casuale - Shuffling dei dati |
In particolare, con riferimento ad una RNA di tipo MLP ad apprendimento supervsionato, l'insieme degli aspetti elencati è opportunamente dettagliato nella Tabella 3.1.
È da porre in evidenza come l'obbiettivo principale che si sta perseguendo, ovvero la specificazione, la progettazione e l'implementazione di un modello neuronale capace di investigare opportunamente il fenomeno indagato, sia in completo accordo con il carattere specifico dei metodi e degli strumenti neurocomputazionali. In relazione al perseguimento dell' obbiettivo qui in analisi, si è deciso, in accordo con la letteratura specializzata (si veda, ad esempio, [Hecht-Nielsen, 1990] e [Hertz et al., 1991]), di "privilegiare" alcuni degli aspetti operativi elencati nella precedente tabella secondo i tre seguenti distinti livelli di "attenzione": un livello di attenzione media (primo livello), un livello di attenzione medio-alta (secondo livello) ed un ultimo livello di attenzione alta (terzo livello).
Attenzione a livello medio
In primo luogo, si è dedicata attenzione a livello medio
. alle operazioni di selezione delle variabili di input e di quelle di output e
. alle operazioni di processamento dei dati. Gli aspetti relativi ad entrambe queste operazioni vengono trattati in dettaglio nella sezione 4.
Attenzione a livello medio-alto
In secondo luogo, si è prestato un livello di attenzione medio-alto
. alle operazioni di selezione delle funzioni di trasferimento, ciò sempre in conformità alle principali linee guida presenti, al riguardo, nella letteratura specializzata. In particolare, per ogni nodo-processore della RNA di tipo MLP ad apprendimento supervisionato (cioè per tutti i suoi nodi ad eccezione di quelli di input) si utilizza la classica funzione logistica (quella presentata nella sottosezione 2.1) nella quale si pone 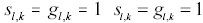 con
con 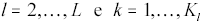 .
.
È da porre in evidenza come alcuni Autori, in relazione all'aggiornamento dei pesi nel corso della fase di training, suggeriscano di utilizzare la seguente versione modificata della regola di apprendimento supervisionato (sempre di tipo batch):
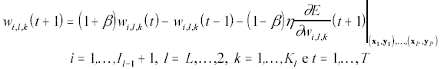
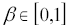 , è un parametro denominato momentum (o fattore di smussamento) in base al quale l'addestramento può risultare più rapido, grazie all'introduzione di un meccanismo di memoria dei valori assunti dai pesi al termine delle precedenti iterazioni dell'algoritmo di apprendimento.
, è un parametro denominato momentum (o fattore di smussamento) in base al quale l'addestramento può risultare più rapido, grazie all'introduzione di un meccanismo di memoria dei valori assunti dai pesi al termine delle precedenti iterazioni dell'algoritmo di apprendimento.
È prestato un livello medio-alto di attenzione anche
. alla gestione del tasso di apprendimento .. In accordo alle metodologie classiche (ad esempio si veda [Hecht-Nielsen,1990]), nel corso della fase di addestramento il tasso di apprendimento deve essere sottoposto con continuità ad azioni di aggiustamento (che ne facciano aumentare o diminuire il valore), ciò allo scopo di ottimizzare il processo di apprendimento stesso del modello neuronale considerato.
Anche
. alle operazioni di inizializzazione casuale e di shuffling dei dati (ovvero di riordinamento casuale dei pattern di input-output)
si è dato un livello di attenzione medio-alto. In particolare, alcuni Autori propongono di addestrare una RNA di tipo MLP ad apprendimento supervisionato sulla base di una serie di diverse configurazioni casuali iniziali, cosicché sia possibile procedere allo sviluppo di più fasi di addestramento, i cui esiti possano in seguito venir tra loro confrontati, allo scopo di prevenire e/o porre rimedio all'insorgere di possibili difficoltà, quali, ad esempio, quelle connesse a situazioni in cui si raggiunga soltanto un minimo relativo della funzione di costo considerata, anziché uno assoluto (questo fenomeno è generalmente noto sotto la denominazione di Local Minimum Pitfall o LMP). Anche lo shuffling dei dati è una proposta che viene comunemente utilizzata nella letteratura specializzata al fine di prevenire il verificarsi di problemi derivanti da uno sviluppo scorretto dell'addestramento, quali, ad esempio, l'apprendimento di relazioni funzionali non corrette tra le variabili di input e quelle di output.
Attenzione a livello alto
Infine, è stato riservato un livello di attenzione alta ai due seguenti aspetti:
. il design architetturale del modello neuronale e
. la regola di stop-learning, ciò perché entrambi questi aspetti si pongono come elementi essenziali nell'ambito della progettazione modellistica (si veda, ad esempio, [Hecht-Nielsen, 1990]).
Per ciò che riguarda il primo aspetto, cioè la struttura architetturale del modello neuronale, si intende considerare attentamente il dimensionamento di una regione "interna" del modello stesso costituita da un unico strato nascosto di nodi, operazione questa che costituisce uno dei punti critici della progettazione di una rete MLP. A tal riguardo si intende specificare e sottoporre a verifica differenti soluzioni architetturali.
In quanto al secondo aspetto meritevole di un livello di attenzione alta, cioè la regola di stop-learning, si è inteso verificare la "bontà" operativa di una versione opportunamente modificata della regola di stopping di tipo MDC presentata nella
sottosezione 2.2.
| Figura 3.1 |
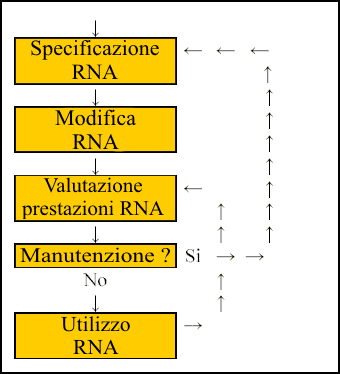 |
In conclusione è da notare che una RNA di tipo MLP non è per sempre. In altri termini, affinché il suo funzionamento prosegua correttamente ed efficacemente nel tempo necessita di un'opportuna "manutenzione". Con quest'ultima affermazione si intende porre in evidenza il fatto che il modello neuronale, al fine di perseguire con continuità nel tempo i propri obiettivi, necessita di essere sottoposto a periodici nuovi addestramenti. In particolare, la finalità di questi nuovi addestramenti risiede nell'esigenza di "aggiornare" la conoscenza della RNA di tipo MLP sugli eventuali cambiamenti strutturali che, relativamente al fenomeno indagato, potrebbero essere intercorsi dal periodo dell'ultimo aggiornamento. Ovviamente, in sede di nuovo addestramento deve essere effettuata ex novo tutta la specificazione del modello neuronale così come presentata in questa sezione. Il "ciclo della vita" del modello neuronale qui proposto si può rappresentare graficamente mediante la diagrammazione a blocchi riportata in Figura 3.1.
Riassumendo, sono molteplici le RNA di tipo MLP da implementare ed indagare al fine di pervenire alla costruzione del modello neuronale ottimale. In particolare, date le varie opzioni operative da considerare così come presentate nella Tabella 3.1, è agevole evincere che questa fase possa essere una di quelle che richieda un elevato numero di risorse sia umane, sia computazionali.
Successivo: Le RNA per la valutazione delle opzioni finanziarie
Sommario: Indice