La fase di apprendimento, con riferimento alle Reti Neurali Artificiali, consiste nell’aggiustamento dei pesi (parametri) in risposta a stimoli esterni. In particolare, nel caso dell’apprendimento supervisionato utilizzato vengono forniti alla rete un vettore di input e l’output desiderato generato dal fenomeno oggetto di studio. L’output generato dalla rete sulla base degli input fornitale è dato da:
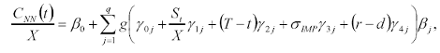
dove:
q numero dei nodi nascosti;
g funzione di trasferimento;
βj e γ.,j parametri.
Come misura dell’errore si assume l’errore quadratico medio e come algoritmo di apprendimento si utilizza l’algoritmo di Levenberg-Marquand, modificando, cioè, i pesi al fine di ridurre l’errore compiuto. Una volta che i pesi sono stati aggiornati, la funzione d’errore viene ricalcolata fino a che, eventualmente, i valori dei parametri non convergano verso una soluzione ottimale, individuando un punto di minimo sulla superficie d’errore.
Tale fase incide in modo rilevante sulla capacità di generalizzazione della rete. L’obiettivo principale, infatti, non è quello di minimizzare l’errore compiuto dalla rete in relazione al training set, garantendo perciò una coincidenza pressoché perfetta tra output generato dalla rete e output desiderato, ma quello di minimizzare l’errore che, idealmente, la rete compie sull’intero insieme dei dati riguardanti il problema affrontato (che abbiamo precedentemente chiamato errore di generalizzazione), garantendo, quindi, che il modello abbia appreso tutti gli aspetti rilevanti che caratterizzano la relazione tra i dati, non confondendola con la parte rumorosa di questi ultimi.
L’andamento di tali errori, con riferimento al numero di iterazioni effettuate, tende ad essere diverso. Mentre l’errore sul training set diminuisce, più o meno regolarmente, ad ogni iterazione, fino a stabilizzarsi ad un punto di minimo, l’errore di generalizzazione tende ad assumere un comportamento dapprima decrescente, fino ad un determinato livello, per poi crescere (problema dell’overtraining). Si pone, quindi, il problema di individuare l’iterazione, e quindi il valore dei parametri, in corrispondenza della quale arrestare la fase di apprendimento, al fine di individuare il valore dei pesi in corrispondenza del minimo dell’errore di generalizzazione.
Un metodo empirico molto utilizzato per ottenere una stima di tale errore è quello della cross-validation. Ad ogni iterazione viene calcolato, oltre all’errore sul training set, anche l’errore commesso su un insieme di esempi (validation set) che non sono stati usati precedentemente, ma che devono essere anch’essi rappresentativi del fenomeno analizzato. La fase di apprendimento verrà arrestata, quindi, in corrispondenza del minimo assunto dall’errore compiuto dalla rete nel validation set.
Nella fase applicativa, tuttavia, il problema dell’overtraining non è stato quasi mai riscontrato. La spiegazione di tale fenomeno può essere imputata alla selezione iniziale fatta sui dati al fine di eliminare gli esempi meno significativi, ed alle caratteristiche dei dati oggetto di studio che, in sostanza, si possono considerare poco rumorosi. Presentiamo ora le prestazioni delle reti neurali artificiali addestrate, rispettivamente per il training set e per il validation set al fine di individuare, sulla base dell’errore commesso, la rete idonea ad essere utilizzata a fini applicativi. Le prove sono state effettuate considerando diverse configurazioni iniziali dei pesi, come suggerito dalla letteratura. Come si può vedere dalla tabella 3
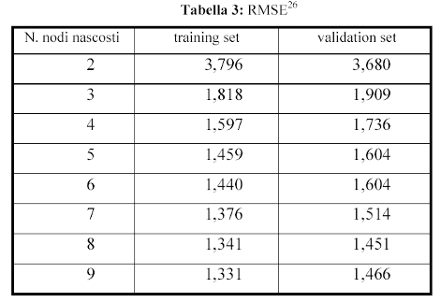
la rete che ottiene i risultati migliori nel validation set è la rete caratterizzata da 8 nodi nello strato nascosto e quindi nel seguito verrà utilizzata a fini applicativi.
M.Billio, M. Corazza, M. Gobbo
Successivo:Risultati ottenuti
Sommario: Indice