Il comportamento sopra descritto si raggiunge dopo la presentazione di molti inputs per un certo numero di volte alla rete, modificando, per ogni presentazione di input solo i pesi che collegano il neurone vincente(Kohonen layer) con i neuroni dello strato di input secondo la formula:
W(k,j)new=W(k,j)old+e*(X(k)-W(k,j)old)
dove W(k,j)= peso sinaptico del collegamento
tra input k e neurone vincente
X(k)= input k_esimo dell input pattern
epsilon= costante di apprendimento(nel range 0.1/1)
In pratica i pesi da aggiornare per ogni presentazione di input sono tanti quanti sono i neuroni di input. In taluni casi si aggiornano con lo stesso criterio, magari usando valori di epsilon decrescenti, anche i pesi dei neuroni di un opportuno vicinato (dimensionalmente sovrapponibile alla parte positiva del cappello messicano).
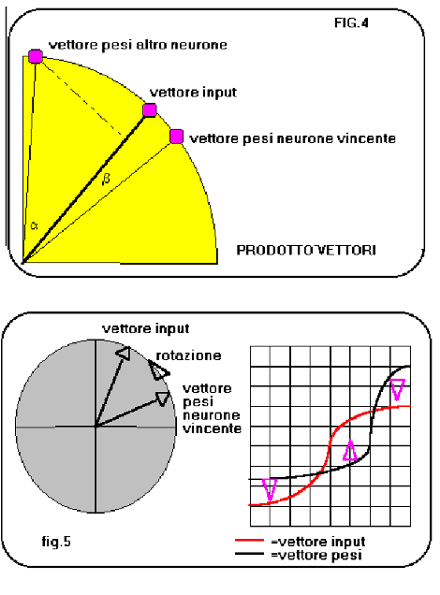
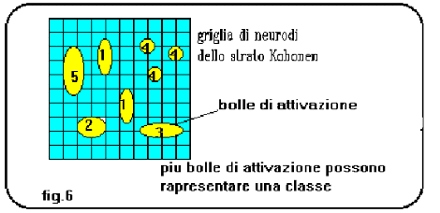
Leggendo con attenzione la formula di apprendimento, ci si accorge che il suo ruolo è quello di ruotare il vettore dei pesi sinaptici verso il vettore di input. In questo modo il neurone vincente viene ancor più sensibilizzato al riconoscimento della forma dell input presentato (fig.4 e fig.5). Questo tipo di reti è stato utilizzato con profitto in applicazioni di riconoscimento immagini e riconoscimento segnali. Quando viene impiegata una rete autoorganizzante, la matrice di neuroni (o neurodi*) di output si presenta con un insieme di bolle di attivazione che corrispondono alle classi in cui la rete ha suddiviso gli inputs per similitudine.
Se noi addestriamo una rete con dati di cui conosciamo a priori la appartenenza a specifiche classi, potremo associare ciascuna delle bolle di attivazione a ognuna di queste classi (fig.6). Il vero fascino dei paradigmi non supervisionati è, però, quello di estrarre informazioni di similitudine tra input patterns (esempio un segnale sonar o radar) molto complessi, lavorando su grandi quantità di dati misurati nel mondo reale.
Questo tipo di rete evidenzia molto bene il fatto che le reti neurali in genere sono processi tipo "data intensive" (con molti più dati che calcoli), anziché "number crunching" (con molti calcoli su pochi dati). Come si può vedere in fig.6 , più bolle di attivazione possono rappresentare una classe di inputs: questo può essere dovuto alla eterogeneità di una classe (che deve essere ovviamente conosciuta) o anche alla sua estensione nello spazio delle forme possibili(in questo caso due pattern agli estremi della classe possono dare origine a bolle di attivazione separate).
*NEURODO: questo termine che deriva dalla composizione di "neurone" e "nodo" è stato proposto da Maureen Caudill ,una autorevole esperta statunitense di reti neurali, con lo scopo di distinguere il neurone biologico(la cui funzione di trasferimento è notevolmente più complessa) dal neurone artificiale. Da ora in poi utilizzeremo questo termine che è probabilmente più corretto.
Luca Marchese
Successivo: Classificatori Supervisionati
Sommario: Indice