Nelle simulazioni e nell'analisi di dati reali che seguono, è stata applicata la metodologia seguente.
Sia m il numero di osservazioni nel campione in esame. Si riscriva la 4.2 in questo modo:
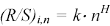 dove k è la costante, n il numero di osservazioni nel sottocampione i
del campione di m osservazioni con
dove k è la costante, n il numero di osservazioni nel sottocampione i
del campione di m osservazioni con
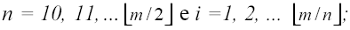
H l'esponente di Hurst. Il termine(R/S)i,n è dato dal rapporto tra il range (Ri,n) e la deviazione standard (Si,n) delle n osservazioni del sottocampione i della serie storica in esame. In particolare il range Ri,n è ottenuto come differenza tra il massimo ed il minimo della sommatoria cumulata degli scarti dalla media delle osservazioni nel sottocampione i; in formula:
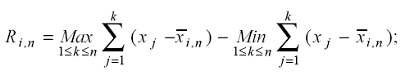
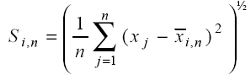 (4.7)
(4.7)
ove con Xi,n , si indica la media delle n osservazioni Xj del sottocampione i. Quindi, per ogni n si calcola la media degli (R/S)i,n ottenendo (R/S)n (figura 4.2):
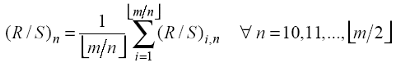 (4.8)
(4.8)
Passando ai logaritmi, la nuova formulazione della 4.2 può essere riscritta come segue:
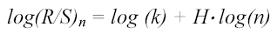 (4.9)
(4.9)
L'esponente H può così essere stimato regredendo linearmente il logaritmo di (R/S)n sul logaritmo di n per ogni 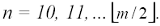
(R/S)n è dunque ottenuto dividendo l'intero campione di m osservazioni in [m/n] sottointervalli contigui di n osservazioni ciascuno ottenendo i dati per la regressione. Si osservi che, essendo [m/n] un numero intero, si applica eventualmente l'arrotondamento per difetto escludendo gli ultimi dati. Per ovviare a tale inconveniente si potrebbero considerare solo quei sottointervalli per i quali m/n è sempre e solo un numero intero. Ciò significherebbe, però, scegliere il campione da analizzare in modo tale che il numero di divisori interi di m sia il più alto possibile, così da disporre di un numero rilevante di dati per la regressione.
In base alle osservazioni fatte sull'analisi R/S si è applicato prevalentemente il primo metodo. Infatti i valori di (R/S)n sia adottando il primo metodo che il secondo, in corrispondenza degli stessi n sono pressoché uguali. Inoltre il maggior numero di dati si presta meglio per l'identificazione più precisa della dura di eventuali manifestazioni che si ripresentano con una certa regolarità nello sviluppo della serie dei dati.
Il frazionamento dell'intero campione di m osservazioni in n sottocampioni di ampiezza crescente ai quali applicare l'analisi R/S, consente di verificare l'esistenza di ricorrenze che si manifestano ad ogni scala. Se queste sono presenti, possono essere la causa di fluttuazioni più o meno intense rispetto a quelle che caratterizzano un random walk. Serie storiche frattali possono presentare trend e cicli e distribuzioni di probabilità frattali. Queste sono caratterizzate da distribuzioni di probabilità statisticamente autosomiglianti, cioè a differenti scale temporali, le caratteristiche statistiche della distribuzione non cambiano (Peters, 1991). È quindi una classe di distribuzioni che rientra nella famiglia delle distribuzioni L-stabili.

Trattamento preliminare dei dati
Nel caso di applicazione dell'analisi R/S a serie storiche di prezzi, vengono prima determinati i rendimenti logaritmici degli stessi: St = ln(pt/pt-1).
La presenza di dipendenza lineare di breve periodo, potrebbe disturbare la stima dell'esponente di Hurst generando un valore di H significativo, cioè maggiore di ½, ma dovuto in parte, o solo, alla dipendenza lineare tra i rendimenti e non all'esistenza di un'effettiva "memoria lunga" all'interno della serie storica studiata. Per eliminare, o cercare di attenuare questo problema, il passo successivo è il calcolo dei residui di un processo autoregressivo di ordine uno (AR(1)) dei rendimenti logaritmici St . Sarà sui residui che verrà applicata l'analisi R/S.
L'uso dei residui di un processo autoregressivo di ordine uno sui rendimenti logaritmici, anziché questi ultimi, non elimina completamente la dipendenza lineare, ma il problema è ridotto ad un valore trascurabile anche nell'ipotesi che l'ordine dell'autoregressivo sia di due o tre (Brock - Dechert - Sheinkman, 1987).
Un' applicazione pratica
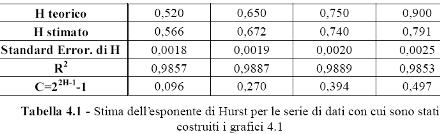
Per questa prima prova si è applicata l'analisi R/S ai dati con cui sono stati elaborati i grafici 4.1 di destra. Come si ricorderà, erano stati generati impostando l'algoritmo di Feder per diversi valori di H. Ci si dovrebbe aspettare che le stime di H confermino i dati impostati o perlomeno vi si avvicinino. In tabella 4.1 sono disponibili i dati di riepilogo delle stime compiute nei quattro casi considerati. I risultati sono abbastanza confortanti se si considera che la simulazione non riesce a riprodurre esattamente l'impostazione teorica del processo; basti pensare al parametro m che, per motivi di computazione, è stato impostato ad un valore inferiore di quello teoricamente richiesto.
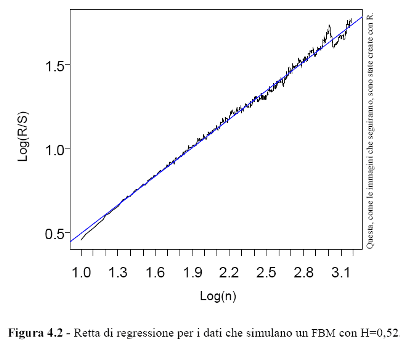
Il dato stimato, effettivamente tende a seguire quello teorico. Rileva l’eccezione del caso H = 0,90 per il quale la stima è relativamente inferiore. Per ogni stima sono indicate anche le specifiche della regressione. La bontà di adattamento è alta, visti gli alti valori dei coefficienti di correlazione della regressione R2 e i bassi errori standard. Sono riportati anche i coefficienti di correlazione di lungo temine C che, si ribadisce, riguardano la correlazione tra gli eventi di intervalli temporali di ampiezze diverse anche molto ampie. Il grafico in figura 4.2, evidenzia la regressione del logaritmo di (R/S)n contro il logaritmo di n per il caso H = 0,52. Per eseguire materialmente l'analisi ci si è avvalsi del software statistico R le cui istruzioni sono riportate in appendice al capitolo.
Giancarlo Fabbro
Successivo: Ricerca di cicli periodici e non periodici I
Sommario: Indice